Monitoring on log files is useful for overseeing application status and allows operators take neccessary actions to prevent incidents. However, sometimes it is hard to find a simple ready-to-use monitor for our specific use case. Here is a tutorial on how to build a very basic monitor on HTTP access logs using a few lines of Python codes. HTTP Access logs looks like the example below:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326 "http://www.example.com/start.html" "Mozilla/4.08 [en] (Win98; I ;Nav)"
Overview
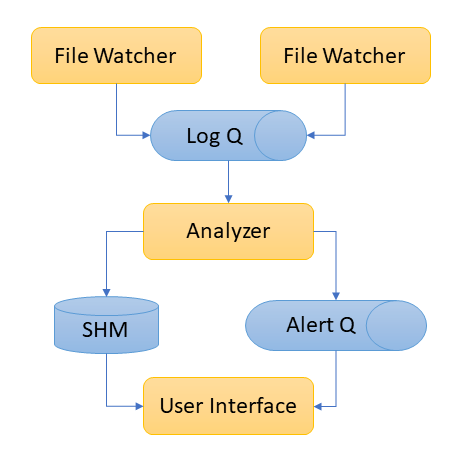
This monitor consists of 3 components:
- File Watcher
- Analyser/Aggregator
- User Interface
The File Watchers read new lines from monitored files, parse the log line and put the extracted information as log items into a message queue dedicated to log influx.
The Analyzer consume log items and update statistic metrics. It uses a memory segment shared with User Interface. When Analyzer finds out some critial metrics are above/below a certain threshold, the Analyzer send an alert item into the alert message queue. Which will be consumed by the User Interface.
The User Interface present the metrics to user and show up alerts when it rises. This program uses a text based UI in the console, periodically update the widgets with statistical information fetched from the shared memory. If there is message in the alert queue, the alert status will change accordingly and shows alert messages in the UI.
Each component uses a process dedicated to its own job. Information flows from File Watcher to Analyzer, then from Analyzer to UI.
When starting the program, the main routine
- initialize message queues, shared memories
- spawn processes of file watcher, analyser and UI
- wait for processes terminate
Here is the launching scripts:
if __name__ == "__main__":
....
monitor = Monitor(log_files, threshold_aps)
monitor.initialize()
monitor.start()
monitor.wait_for_finish()
Now let's make the 3 components to monitor our log files, starting from File Watcher.
File Watcher
When creating watcher process, we pass the file to watch and the message queue to which it should send parsed metrics.
class Monitor(object):
....
def initialize(self):
# watch files
for filename in self._filenames:
fw = FileWatcher(filename)
proc = Process(target=fw.watch, args=(self._log_q, self._running))
self._processes.append(proc)
....
When file watcher is running, it reads new lines from wathced files, parse them into metrics and send them to message queue. One thing worth our attention is that when it has read the last line, next readline() will return an empty line. In this case we let it sleep a while and try another read later.
class FileWatcher(object):
def __init__(self, filename, timeout=DEFAULT_READLINE_TIMEOUT):
try:
self._file_handle = open(filename, 'r')
self._file_handle.seek(0, os.SEEK_END)
except FileNotFoundError as err:
print(err)
raise err
def readline(self):
line = None
sleep_count = 0
while not line:
line = self._file_handle.readline()
if line == '':
time.sleep(DEFAULT_READLINE_SLEEP)
return line
def watch(self, log_queue, running):
parser = LogParser()
while running.value == 1:
line = self.readline()
if line == '':
continue
remotehost, rfc931, authuser, date, request, status, size = parser.parse_line(
line)
if not request:
continue
section = parser.section_from_request(request)
try:
size = int(size)
except ValueError:
size = 0
log_item = LogItem(remotehost, rfc931, authuser,
date, request, status, size, section)
log_queue.put(log_item)
Now we have an influx of information, time to aggregate them into meaningful metrics.
Analyser/Aggregator
The Analyser takes individual metrics from the messages queue, aggregate them into metrics that we care and update the memory shared with UI process. Below is a snippet from the aggregate routine showing how the hit count is updated:
- aggregator receives a log metric object from the message que. This metric object is generate from an access, meaning we have a hit on a webpage.
- we increase the hit count
- if now is the time to update metrics, we update the shared memory
self._aggregated_statisticsusing the new result.
def aggregate(self):
....
next_aggregate_time = datetime.now() + timedelta(seconds=self._frame_interval)
self._aggregated_statistics['next_aggregate_time'] = next_aggregate_time
while self._running.value == 1:
try:
log_item = self._log_q.get(timeout=LOG_QUEUE_TIMEOUT)
frame_hit_count = frame_hit_count + 1
....
except queue.Empty as err:
log_item = None
# aggregate results of frame
if datetime.now() > next_aggregate_time:
lps = 1.0 * frame_hit_count / self._frame_interval
self._aggregated_statistics['lps_frame'] = lps
....
# new frame
frame_hit_count = 0
frame_heat_map = dict()
next_aggregate_time = datetime.now() + timedelta(seconds=self._frame_interval)
self._aggregated_statistics['next_aggregate_time'] = next_aggregate_time
Having the aggregated metrics, now we can present them to operators thorugh the User Interface.
User Interface
The User Interface get metrics from the shared memory and messages queues populated by the Analyser/Aggregator process. The final presentation can be a web page or simple terminal outputs. Here I use npyscreen package to build a Text UI, handy when using SSH terminal interface.
A simple way to use npyscreen is by extending the npyscreen.NPSAppManaged class. Here we pass the shared memory stats_dict and the message queue receiving alerts in its __init__ function.
The main interface is a Form Dashboard class containing the widgets to show various metrics, added by the function onStart.
class MonitorUI(npyscreen.NPSAppManaged):
def __init__(self, stats_dict={}, alert_q=None, running=None):
super().__init__()
self._stats_dict = stats_dict
self._running = running
self._alert_q = alert_q
def onStart(self):
self.addForm('MAIN', Dashboard, name='HTTP Log Monitor',
stats=self._stats_dict, alert_q=self._alert_q)
...
The Dashboard class mainly has to do 2 things: place widget at desired place (create) and update the values to display (while_waiting).
After updating widgets' values in the function while_waiting, do not forget to explicitly calls its display() method to render the widget.
class Dashboard(npyscreen.Form):
....
def create(self):
self.keypress_timeout = 10
# press Escape to quit
self.how_exited_handers[npyscreen.wgwidget.EXITED_ESCAPE] = self.exit_application
height, width = self.useable_space()
height_lps_status_box = 5
rely = 2
self._lps_box = self.add(TrafficBox, name='Traffic', editable=False,
relx=2,
rely=rely,
max_width=(width // 2 - 4),
max_height=height_lps_status_box)
self._lps_box.set_values(val_10s=0, val_2m=0, val_lifetime=0)
....
def while_waiting(self):
self._lps_box.set_values(
val_10s=self._stats.get('lps_frame', 0),
val_2m=self._stats.get('lps_scene', 0),
val_lifetime=self._stats.get('lps_lifetime', 0)
)
self._lps_box.display()
Launch
Now let's put these components together and launch the monitor. We use the multiprocessing library in Python to run these 3 kinds of processes simultanously.
- create shared resources such as shared memory and message queue using
ManagerandQueue - create process context using entry function and arguments
Process(target=fw.watch, args=(self._log_q, self._running)) - start the process
process.start() - let the parent process wait for children's termination
for proc in self._processes: proc.join()
from multiprocessing import Process, Queue, Value, Manager
from file_watcher import FileWatcher
from user_interface import MonitorUI
....
class Monitor(object):
def __init__(self, filenames, threshold_lps,
frame_interval=REFRESH_INTERVAL,
scene_interval=ALERT_WINDOW):
self._filenames = filenames
self._processes = list()
self._resource_manager = Manager()
self._log_q = Queue()
self._alert_q = Queue()
self._running = Value('b', 1)
self._alert_threshold = Value('L', threshold_lps)
self._aggregated_statistics = self._resource_manager.dict()
self._ui = MonitorUI(self._aggregated_statistics,
self._alert_q, self._running)
....
def initialize(self):
# watch files
for filename in self._filenames:
fw = FileWatcher(filename)
proc = Process(target=fw.watch, args=(self._log_q, self._running))
self._processes.append(proc)
# aggregate statistics
proc = Process(target=self.aggregate)
self._processes.append(proc)
# UI
proc = Process(target=self._ui.run)
self._processes.append(proc)
def start(self):
self._aggregated_statistics['start_time'] = datetime.now()
self._aggregated_statistics['next_aggregate_time'] = datetime.now()
for process in self._processes:
process.start()
def stop(self):
self._running.value = 0
def wait_for_finish(self):
for proc in self._processes:
proc.join()
def aggregate(self):
....
if __name__ == "__main__":
....
monitor = Monitor(log_files, threshold_aps)
monitor.initialize()
monitor.start()
monitor.wait_for_finish()
Sliding Window
Many metrics are calculated using a sliding window over a subset of most recent N minutes or last N samples. This has many implementations. Here is one of them, using a circular buffer, a metaphor of frame and scene.
Imagine that the Analyzer is required to calculate average traffic during a sliding time window of 2 minutes and the average traffic for last 10 seconds. This is quite similar to filming a video. We can consider the statistics collected every 10 seconds as a frame and the sliding time windows of 2 minutes as a scene. A scene is composed of multiple frames in a movie, so is the 2 minute statistics composed as an aggregation of 12 times of statistics over 10 seconds.
Thus we use a circular buffer to keep every frame containing 10s of statistics in the scene of 2 minutes. Thus it contains 12 items in the buffer (2min / 10s = 12). For calculating average traffic over 2 minutes, we just need to sum up the access counter of each item in the buffer and then divided by duration of 2 minutes. Any metric can be calculated this way, as long as it is an aggregation function.
Here is the code calculating traffic for last 10 seconds, 2 minutes and since the beginning.
def aggregate(self):
total_hit_count = 0
frame_hit_count = 0
# circular buffer for hit counter in alert window
frames_in_scene_hit_counts = [0 for _ in range(self._frames_per_scene)]
frame_index_in_scene = 0
start_time = self._aggregated_statistics['start_time']
alter_start_time = start_time + timedelta(seconds=self._scene_interval)
self._aggregated_statistics['lps_frame'] = 0
self._aggregated_statistics['lps_scene'] = 0
self._aggregated_statistics['lps_lifetime'] = 0
next_aggregate_time = datetime.now() + timedelta(seconds=self._frame_interval)
while self._running.value == 1:
try:
log_item = self._log_q.get(timeout=LOG_QUEUE_TIMEOUT)
frame_hit_count = frame_hit_count + 1
hit_count = frame_heat_map.get(log_item.section, 0)
except queue.Empty as err:
log_item = None
# aggregate results of frame
if datetime.now() > next_aggregate_time:
lps = 1.0 * frame_hit_count / self._frame_interval
self._aggregated_statistics['lps_frame'] = lps
total_hit_count = total_hit_count + frame_hit_count
time_delta = datetime.now() - start_time
total_lps = total_hit_count / time_delta.seconds
self._aggregated_statistics['lps_lifetime'] = total_lps
frames_in_scene_hit_counts[frame_index_in_scene] = frame_hit_count
frame_index_in_scene = (
frame_index_in_scene + 1) % self._frames_per_scene
if datetime.now() > alter_start_time:
scene_lps = sum(frames_in_scene_hit_counts) * \
1.0 / self._scene_interval
else:
scene_lps = total_lps
self._aggregated_statistics['lps_scene'] = scene_lps
# new frame
frame_hit_count = 0
next_aggregate_time = datetime.now() + timedelta(seconds=self._frame_interval)
References
- The code of example can be found on my GitHub repository.
- Python documentation on multiprocessing
- npyscreen package